
Rédigé par Hardik Pandya
Introduction : Comprendre l'évolution de l'architecture de données
Au cours de mes 20 ans et plus de carrière en développement logiciel, j'ai travaillé sur de nombreux projets, du design web aux frameworks Java/J2EE/MVC en passant par les bases de données OLTP/OLAP. Au cours de la dernière décennie, j'ai fait la transition vers l'ingénierie des données.
En passant d'ingénieur logiciel à ingénieur/architecte de données travaillant comme consultant, j'ai été témoin de l'évolution de l'architecture de données en travaillant avec des entrepôts de données traditionnels, des bases de données NoSQL et des écosystèmes de mégadonnées, de Hadoop à Spark, Kafka, CDC et les lacs de données. J'ai vu l'architecture de données évoluer de systèmes d'entreposage centralisés et rigides vers des systèmes distribués et agiles.
Aujourd'hui, le maillage de données (Data Mesh) n'est pas juste un mot à la mode. C'est un changement stratégique dans notre façon de penser la propriété, la gouvernance et l'accès aux données.
Dans ce guide, je veux partager ce que j'ai appris d'implémentations concrètes pour aider les autres à passer des systèmes patrimoniaux aux plateformes de maillage de données évolutives et distribuées.
Je vais utiliser des exemples non conventionnels pour rendre cette lecture excitante, amusante et compréhensible. Pour aider à illustrer l'évolution, j'utiliserai des métaphores culinaires et alimentaires, des concepts familiers à nous tous, pour expliquer comment les architectures de données ont évolué au cours des deux dernières décennies. Allons-y!
Des cuisines étoilées Michelin aux festivals de camions de rue : Comment je vois l'architecture de données

1. L'entrepôt de données traditionnel : Une cuisine étoilée Michelin
Les entrepôts de données existent depuis un certain temps, bien qu'ils nécessitaient un petit groupe de spécialistes pour les opérer. Ils me rappellent les restaurants étoilés Michelin : strictement contrôlés, méthodiques et offrant constamment une haute qualité. Je me souviens d'énormes vues matérialisées construites sur des dimensions à évolution lente, fonctionnant sur des appliances BI monolithiques où les tâches ETL pouvaient prendre plus de 20 heures à compléter.
L'approche traditionnelle de l'entrepôt de données suit un processus linéaire :
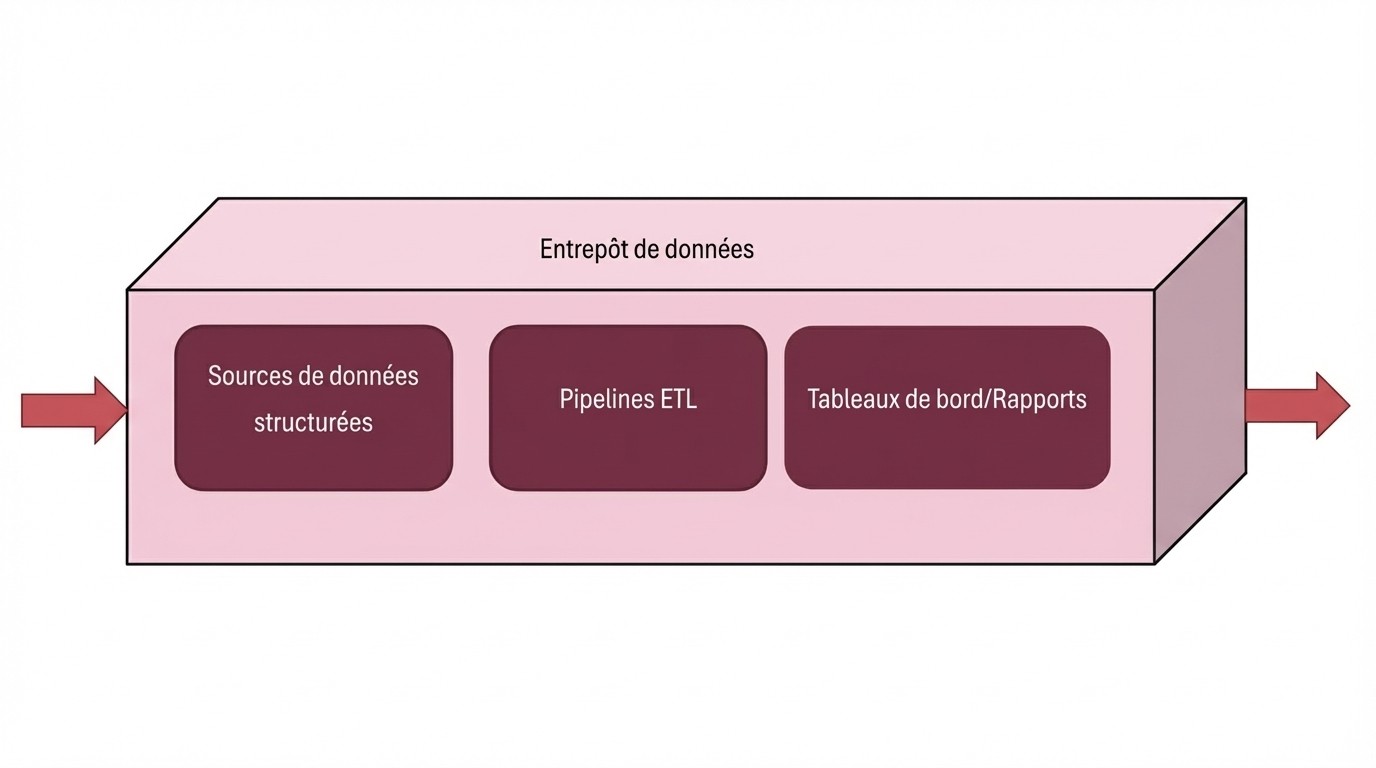
Sources de données → Pipeline ETL → Entrepôt de données → Tableaux de bord/Rapports
Cette approche offre plusieurs avantages :
Qualité de données exceptionnelle : Comme avoir seulement les meilleurs chefs dans la cuisine, les entrepôts de données assurent qu'aucune donnée mystérieuse ou douteuse n'arrive au produit final
Standardisation parfaite : Chaque sortie est formatée de manière cohérente et fiable
Nettoyage de données impeccable : Il n'y a pratiquement aucune chance de trouver des données corrompues ou incohérentes dans vos rapports finaux
Cependant, cette approche a aussi des limitations importantes :
Agilité lente : Vous voulez quelque chose de nouveau? Vous devrez remplir une demande et attendre l'approbation des équipes BI et analytique
Latence élevée : Vos insights pourraient arriver après que vous ayez déjà pris la décision pour laquelle vous en aviez besoin
Flexibilité limitée : Vous êtes restreint à ce qui est sur le menu prédéterminé - pas de commandes personnalisées ou d'approches innovantes
2. Le lac de données : Une expérience d'entrepôt géant Costco
Alors que les organisations voulaient plus de flexibilité, les lacs de données ont émergé : de grands environnements inclusifs acceptant toutes les sources de données. Pensez à un entrepôt Costco : tout est disponible, mais c'est facile de perdre le fil.

La structure a changé pour :
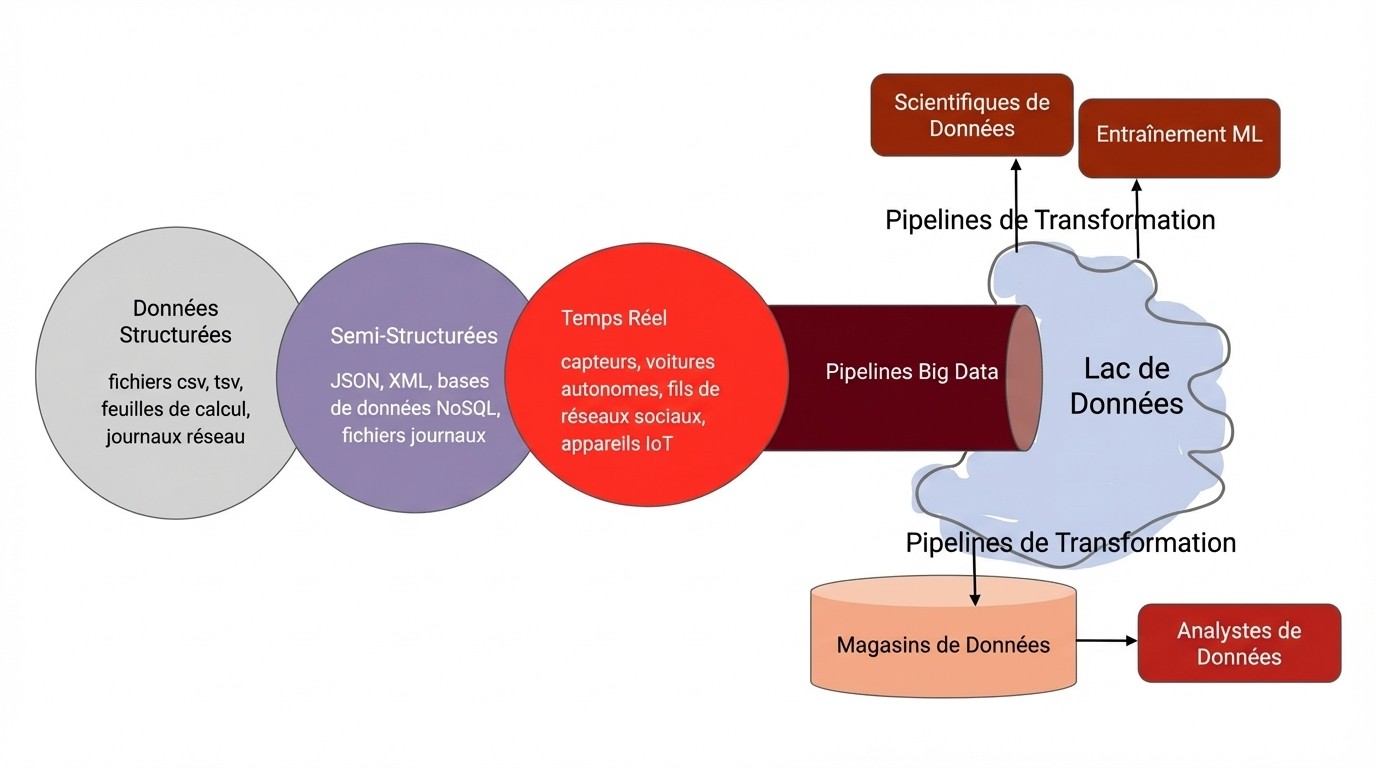
D'après mon expérience, les lacs de données offrent des avantages remarquables :
Variété de données complète : Tout est disponible - données structurées, semi-structurées et non structurées
Accès à la demande : Pas besoin d'attendre que les équipes d'ingénierie de données traitent vos demandes
Parfait pour l'innovation : Les scientifiques de données peuvent expérimenter et explorer sans contraintes traditionnelles
Mais j'ai aussi rencontré des défis importants avec les lacs de données :
Qualité de données imprévisible : Vous ne savez jamais ce que vous allez obtenir, parce que certaines données peuvent être brutes, non étiquetées ou même corrompues
Expertise requise : Les équipes ont besoin de compétences techniques importantes pour extraire de la valeur des données brutes
Complexité écrasante : Sans gouvernance appropriée, les lacs de données deviennent rapidement des marécages de données
3. La révolution du maillage de données (Data Mesh) : Un festival de camions de rue avec infrastructure partagée

Ce qui rend le maillage de données différent
Après avoir travaillé avec des entrepôts traditionnels et des lacs de données, j'ai trouvé que le maillage de données représente le meilleur des deux mondes. Pensez-y comme un festival de camions de rue avec des règles et une infrastructure partagées, mais où chaque camion (domaine) opère indépendamment tout en suivant des standards communs.
Pour comprendre le maillage de données, allons plus en profondeur.
Un maillage de données comprend quatre composantes clés :
Équipes de domaine (les opérateurs indépendants)
Produits de données (ce que chaque domaine produit)
Gouvernance (les standards partagés)
Consommateurs de données (qui utilise les produits de données)
Les quatre piliers de l'architecture maillage de données
Les architectures maillage de données réussies reposent sur quatre principes fondamentaux :
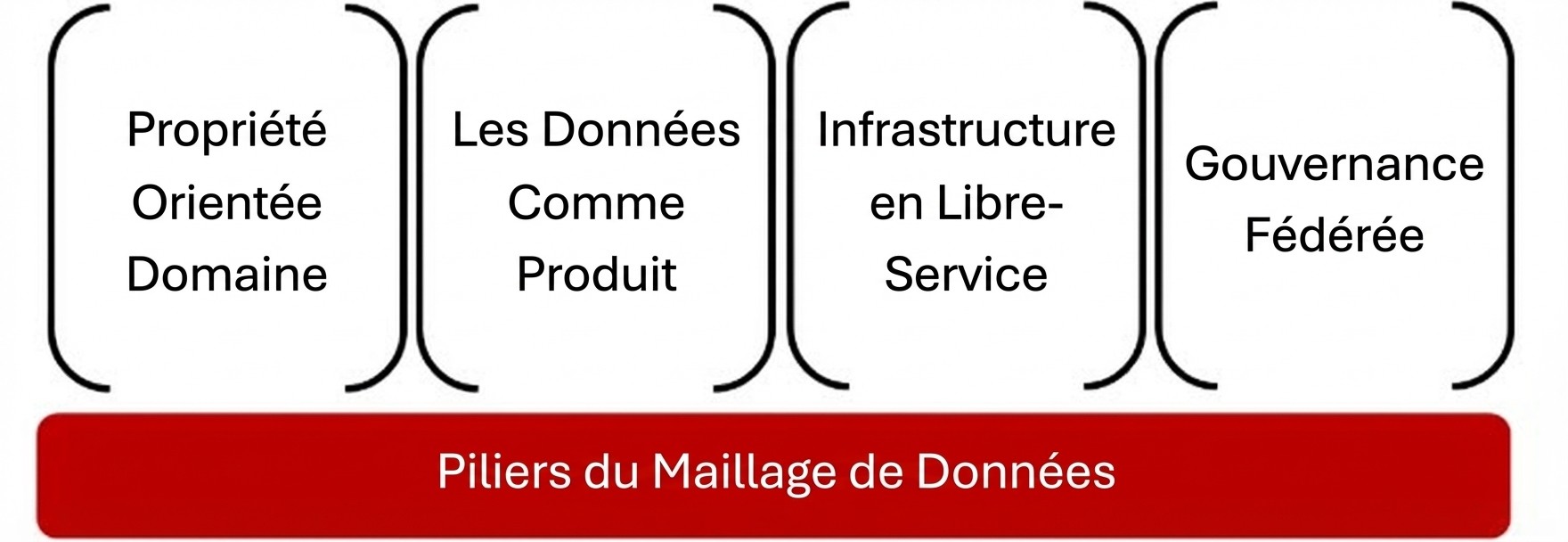
1. Propriété orientée domaine
Chaque domaine d'affaires possède et gère ses propres données, tout comme chaque camion de rue gère sa propre cuisine et son menu. En pratique, cela signifie que les équipes marketing possèdent les données d'interaction client, les équipes de ventes possèdent les données de transactions et de pipeline, et les équipes d'opérations possèdent les données de logistique et de chaîne d'approvisionnement.
2. Les données comme produit : Le concept central du maillage de données
Les données sont livrées avec qualité, documentation et propriété claire - similaire à comment chaque camion de rue sert des plats spécialisés. Cela inclut une documentation et des métadonnées complètes, des garanties de qualité et des engagements SLA, des contrats de données et APIs clairs, plus un soutien et une maintenance continus.
3. Infrastructure en libre-service
Les équipes utilisent des outils partagés pour construire et gérer les produits de données indépendamment, comme les camions de rue partageant les services publics du festival. Cela inclut des plateformes communes de traitement de données, des outils partagés de surveillance et d'observabilité, des pipelines de déploiement standardisés, et des contrôles de sécurité et d'accès unifiés.
4. Gouvernance fédérée
Des standards partagés assurent la sécurité et la conformité à travers tous les domaines, similaire aux règles du festival assurant la salubrité des aliments et une excellente expérience pour tous. Cela inclut des standards communs de qualité de données, des politiques de sécurité unifiées, des formats de métadonnées standardisés, et des contrôles de confidentialité et de conformité cohérents.
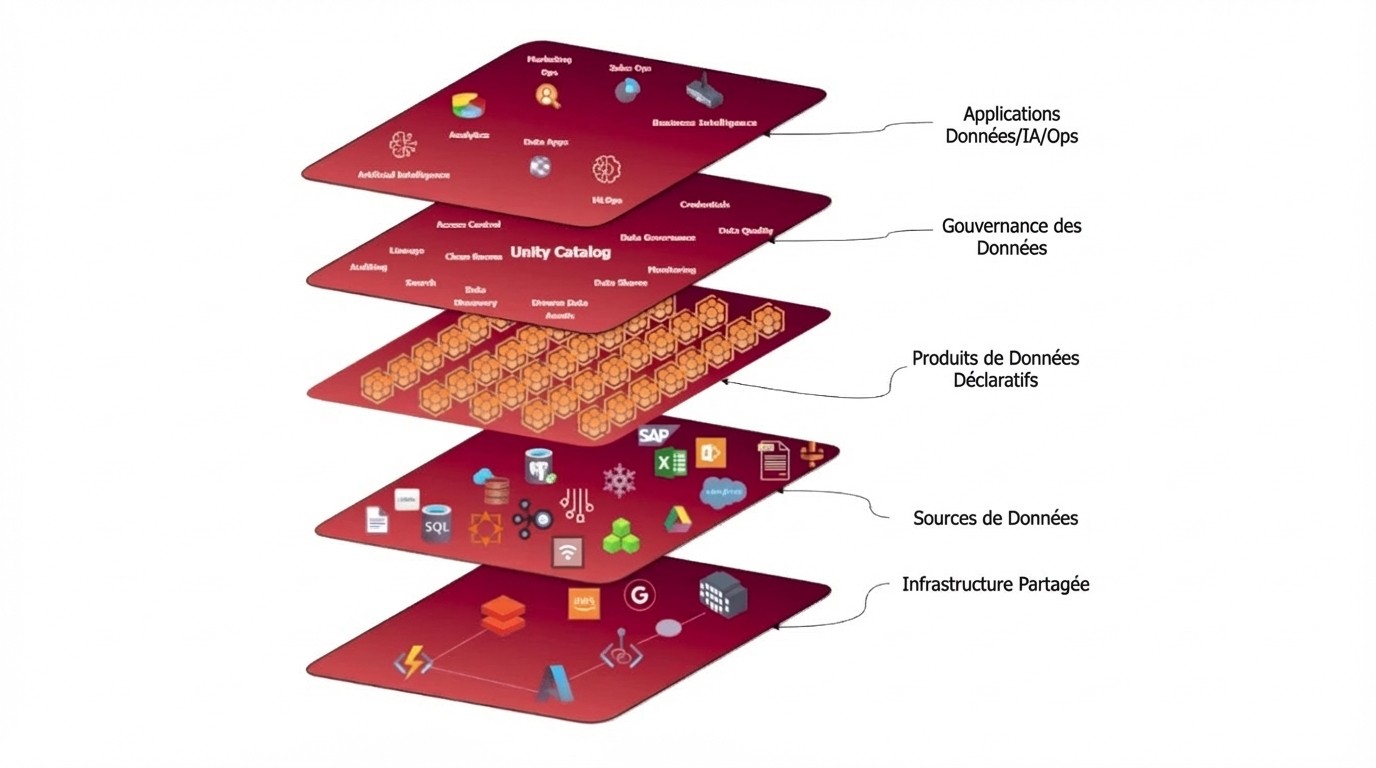
Qu'est-ce qu'un produit de données?
Comprendre les produits de données en pratique
Lorsque je travaille avec des parties prenantes non techniques, j'explique les produits de données comme des plats signature dans un restaurant. Chaque produit de données comprend plusieurs composantes clés:
Les ingrédients (Sources de données)
Ce sont les matières premières - d'où proviennent vos données. Celles-ci peuvent inclure des bases de données clients, des journaux de transactions, des APIs externes, des données de capteurs IoT et des flux de données tiers.
La recette (Configuration)
Les étapes réelles de transformation et d'enrichissement impliquent typiquement le nettoyage et la normalisation des données, l'ingénierie de caractéristiques, l'agrégation et la synthèse, plus des capacités de traitement en temps réel ou par lots.
Le Processus de Cuisson (Traitement)
Les étapes réelles de transformation et d'enrichissement impliquent généralement le nettoyage et la normalisation des données, l'ingénierie des caractéristiques, l'agrégation et la synthèse, ainsi que des capacités de traitement en temps réel ou en lot.
Le plat servi (Données publiées)
Le produit de données final, prêt à utiliser, que les consommateurs peuvent accéder inclut des ensembles de données propres et validés, des APIs pour l'accès en temps réel, une documentation et des métadonnées complètes, plus des exemples d'utilisation et des tutoriels.
Assurance qualité (Surveillance)
Assurer que les données restent fraîches, précises et disponibles est implémenté à travers des vérifications automatisées de qualité de données, de la surveillance de performance, des systèmes d'alerte et des analyses d'utilisation.
Le menu (Réutilisabilité)
Les produits de données peuvent être partagés et réutilisés par plusieurs équipes, similaire à comment les plats populaires apparaissent sur plusieurs menus. Cela peut être réalisé via une API de contrats de données.
Par exemple, un produit de données « Client 360 » pourrait combiner des données CRM, des analyses web et des tickets de support en une vue unique et gouvernée que les équipes marketing, ventes et support peuvent toutes consommer via des APIs standardisées.
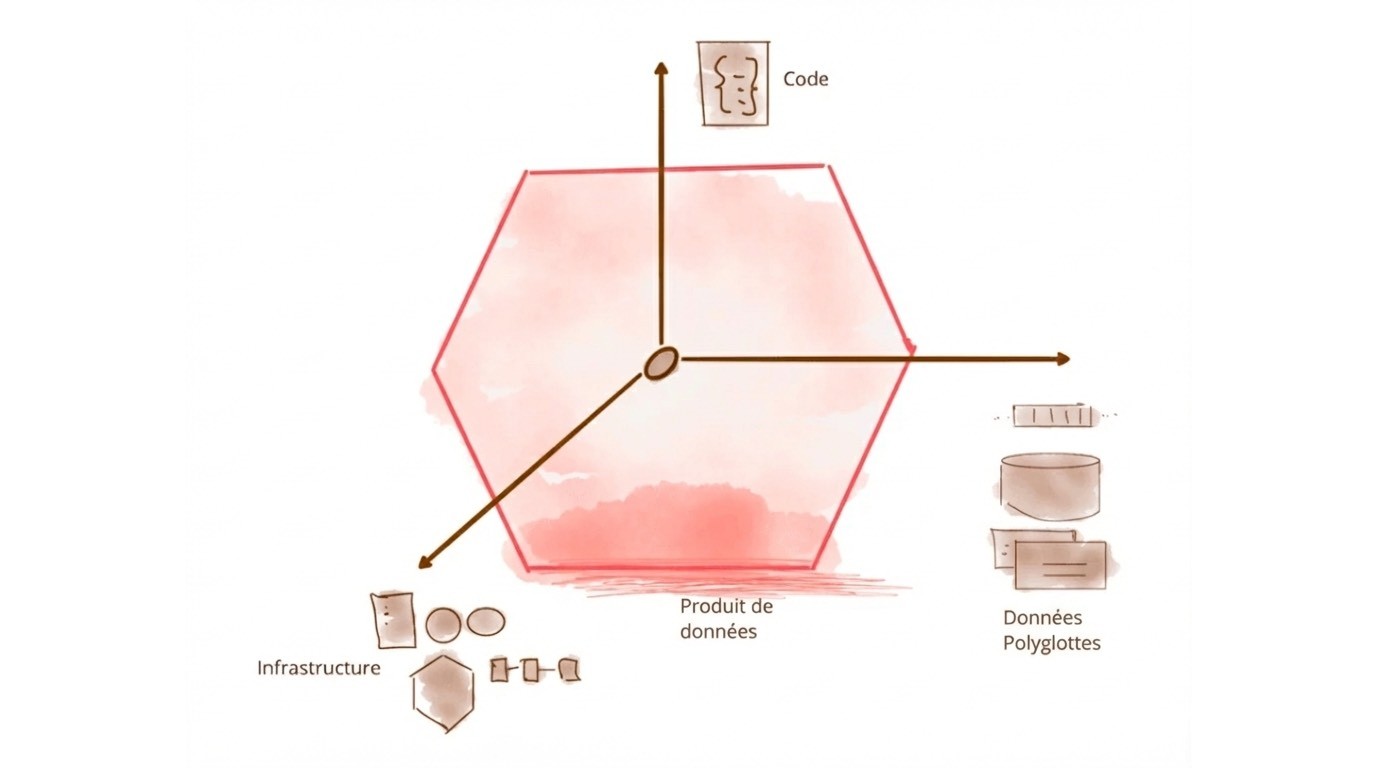
Comprendre les produits de données déclaratifs
Les produits de données déclaratifs représentent une avancée importante dans notre façon de définir et gérer les pipelines de données. Plutôt que d'écrire du code impératif qui décrit comment traiter les données, les produits de données déclaratifs spécifient à quoi le résultat final devrait ressembler. Pensez-y comme commander d'un menu plutôt qu'écrire des instructions de cuisson : vous décrivez ce que vous voulez, et la plateforme gère les détails d'exécution.
Composantes clés des produits de données déclaratifs
Les produits de données déclaratifs efficaces incluent :
Configuration du processus
La configuration du processus implique l'établissement de dépendances internes et externes avec une spécification claire des sources de données et des consommateurs en aval, la définition d'objets de données à travers des schémas structurés et des contrats de données, et l'implémentation de la gestion des calendriers et SLA avec une planification automatisée qui inclut la surveillance et les alertes SLA intégrées.
Architecture modulaire
L'architecture modulaire supporte plusieurs objets de données pour des produits de données complexes avec plusieurs ensembles de données de sortie, permet le regroupement de sous-produits de données pour l'organisation logique d'objets de données liés, et fournit des composants réutilisables avec logique de traitement partagée et fonctions de transformation.
Publication et découverte
Les fonctionnalités de publication et découverte incluent la publication automatique avec intégration transparente aux catalogues de données et systèmes de découverte, la gestion de références qui fournit un suivi automatique des dépendances et gestion de la lignée, et le contrôle de version avec des capacités intégrées de gestion du versionnage et des changements.
Avantages de l'approche déclarative
L'approche déclarative offre plusieurs avantages clés.
Les équipes expérimentent une complexité réduite en se concentrant sur la logique d'affaires plutôt que sur les préoccupations d'infrastructure.
Améliore la maintenabilité : Les changements aux exigences deviennent plus faciles à implémenter et tester.
Meilleure gouvernance assure la conformité automatique aux standards et politiques organisationnels.
Collaboration améliorée fournit des spécifications claires et lisibles que les parties prenantes non techniques peuvent comprendre.
L'avenir du Maillage de données
Tendances émergentes que j'observe
Alors que je continue à travailler avec des architectures maillage de données, je vois plusieurs tendances importantes :
1. Automatisation accrue
Découverte intelligente de données : Outils alimentés par IA qui identifient et classifient automatiquement les actifs de données
Surveillance automatisée de la qualité : Systèmes d'apprentissage automatique qui détectent et préviennent les problèmes de qualité de données
Pipelines auto-réparateurs : Systèmes qui récupèrent automatiquement des pannes courantes
2. Gouvernance améliorée
Politique comme code : Règles de gouvernance implémentées comme code exécutable
Conformité dynamique : Surveillance et application de la conformité en temps réel
Confidentialité dès la conception : Contrôles de confidentialité et mécanismes de protection des données intégrés
Plateformes Low-Code/No-Code : Outils visuels qui permettent aux utilisateurs d'affaires de créer des produits de données
Environnements de développement intégrés : Plateformes complètes qui rationalisent l'ensemble du cycle de vie du produit de données
Cadres de test avancés : Outils sophistiqués pour tester les produits de données dans des environnements similaires à la production
3. Maillage de données agentique
Le maillage de données agentique représente la convergence des agents IA avec l'architecture de données distribuée. Dans ce paradigme émergent, des agents autonomes peuvent découvrir, accéder et orchestrer des produits de données à travers les domaines pour répondre à des demandes analytiques complexes. Plutôt que les humains assemblant manuellement les données de plusieurs domaines, les agents IA naviguent le mesh, comprennent les contrats de données et composent des insights multi-domaines automatiquement.
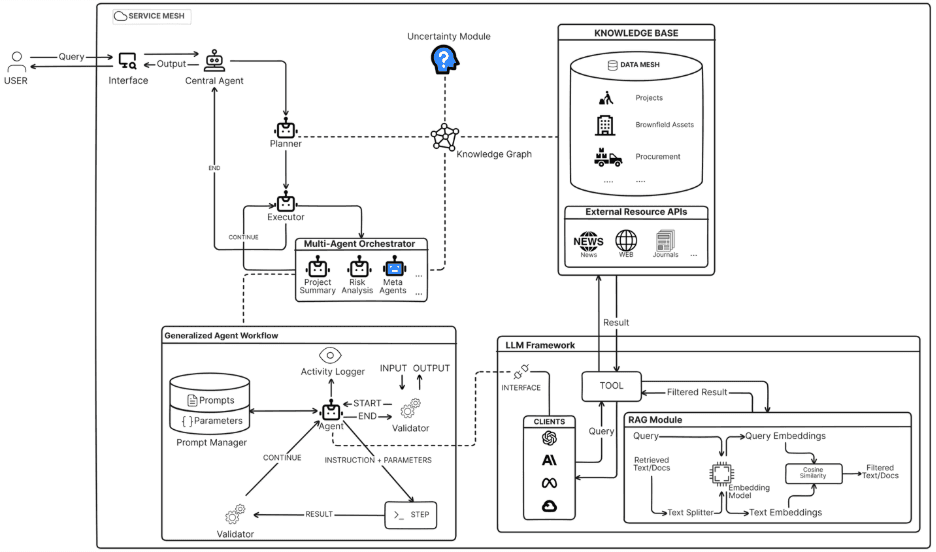
Flux de Travail Généralisé Multi-Agent
Crédit image: https://arxiv.org/html/2412.00224v1
Cette approche permet :
Des requêtes en langage naturel qui couvrent plusieurs domaines d'affaires
La composition automatique de produits de données basée sur l'intention de l'utilisateur
La mise en cache intelligente et l'optimisation de requêtes inter-domaines
Des analyses en libre-service sans nécessiter de connaissances techniques approfondies
Meilleures pratiques du Maillage de données
Les organisations envisageant l'adoption du maillage de données devraient:
Commencer petit : Commencer avec un projet pilote dans un seul domaine
Construire des services robustes : Mieux tester vos services de plateforme avec des versions stables, des tests unitaires, une couverture de code et des processus CI/CD.
Tester, tester et tester : Construire, déployer et tester toutes les fonctionnalités de la plateforme sur un nœud de maillage de données de test pour DEV/UAT/PROD avant de déployer les fonctionnalités sur les nœuds de maillage de données des consommateurs.
Investir dans la formation : S'assurer que les équipes comprennent les principes du maillage de données avant l'implémentation.
Se concentrer sur la gouvernance : Établir des standards et politiques clairs dès le début.
Choisir la bonne pile technologique : Sélectionner des outils qui supportent les architectures distribuées.
Planifier le changement culturel : Adresser la résistance organisationnelle à la propriété distribuée des données.
Résumé : Maillage de données et au-delà
La transition des entrepôts de données traditionnels vers le maillage de données n'est pas toujours facile, mais les avantages sont substantiels.
Les organisations qui implémentent avec succès des architectures maillage de données voient une qualité de données améliorée, un temps d'obtention d'insights plus rapide, une meilleure collaboration inter-équipes et des capacités d'innovation accrues.
Pour moi, le maillage de données n'est pas juste une nouvelle architecture. C'est une philosophie. Il rapproche les données de ceux qui en ont besoin, quand ils en ont besoin, et dans la forme qu'ils peuvent utiliser.
Nous garderons une plongée en profondeur dans le Data Fabric pour une autre fois, mais je veux m'assurer que vous obtenez une valeur immédiate de ce guide. Ci-dessous se trouve une comparaison des architectures de données clés pour vous aider à déterminer quand chaque approche est la plus efficace.
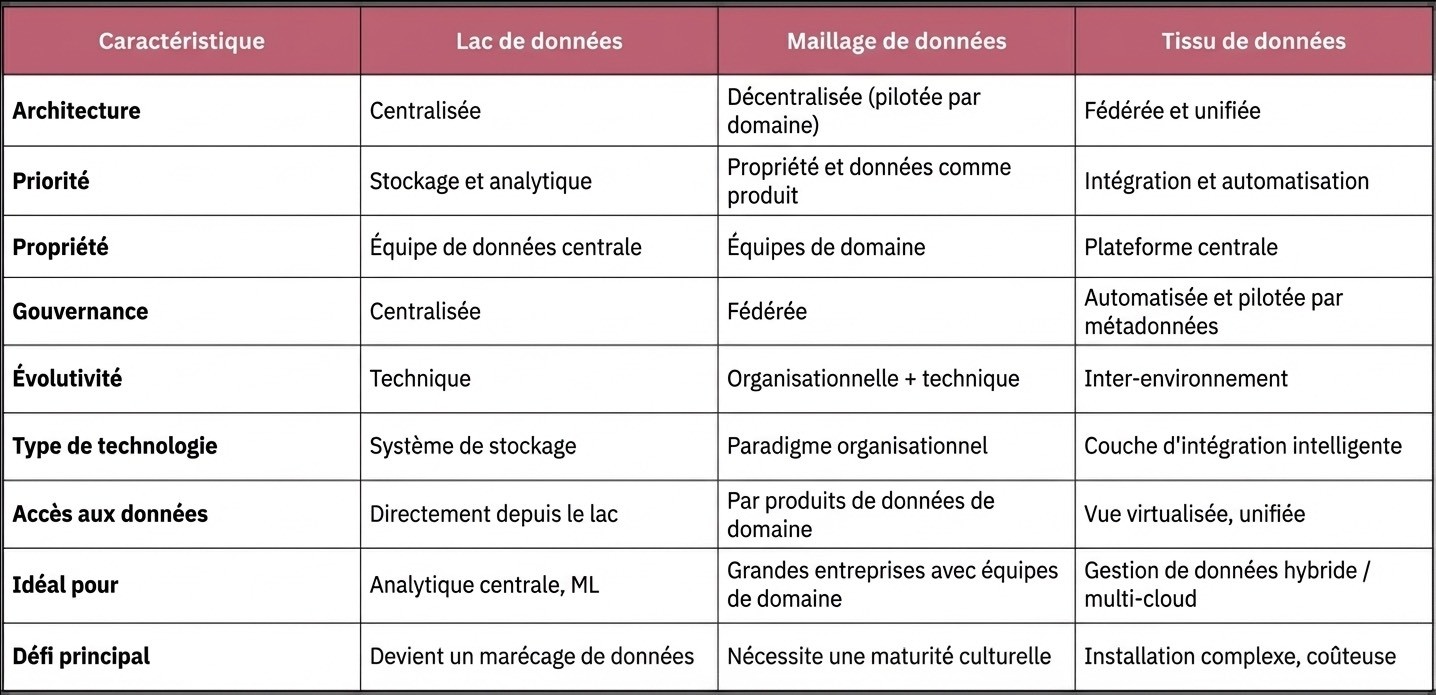
Quand utiliser quoi
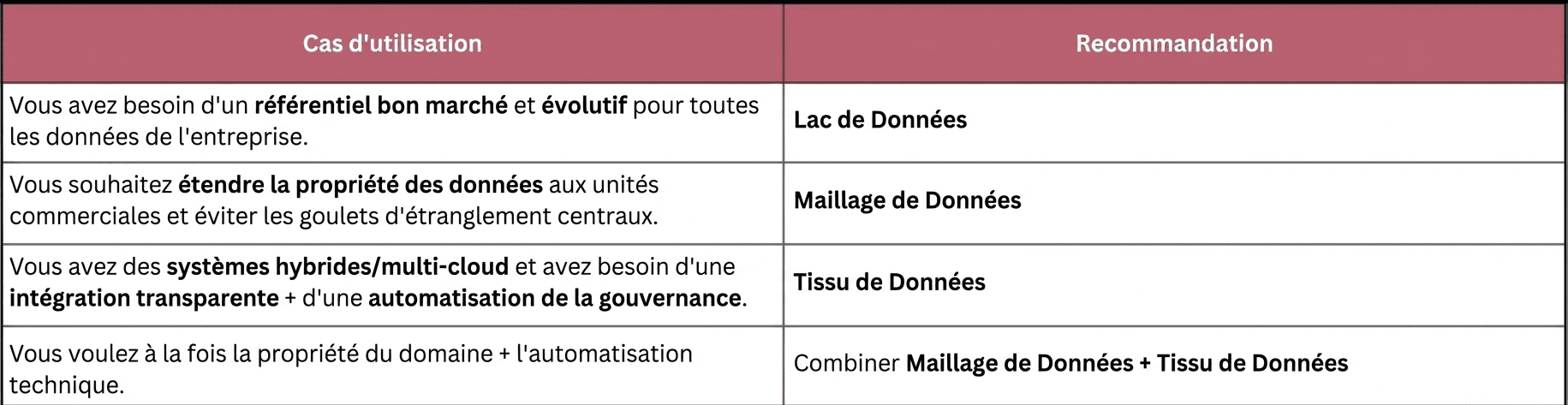
On pourrait argumenter que nous n'abandonnons pas simplement le contrôle centralisé. Nous gagnons en autonomie, agilité et innovation. Le festival de camions de rue est ouvert, et chaque domaine a une chance de concocter quelque chose de génial.
L'avenir des données est distribué et autonome. Le maillage de données est comment nous y arrivons.
Dans notre prochain article, nous plongerons en profondeur dans l'implémentation pratique des plateformes maillage de données, explorant l'architecture du monde réel, les décisions d'outillage et les stratégies d'activation de plateforme qui rendent le maillage de données réussi dans les environnements de production.
D'ici là, continuez à bâtir de meilleurs systèmes de données 😊





