
Written by Hardik Pandya
Introduction: Understanding Data Architecture Evolution
In my 20+ years working in software development, I have worked on numerous projects from web design to Java/J2EE/MVC frameworks and OLTP/OLAP databases. In the last decade, I transitioned into data engineering.
From being a software engineer to data engineer/architect working as a consultant, I've witnessed how data architecture has evolved working with traditional data warehouses, NoSQL DBs and big data ecosystems, from Hadoop to Spark, Kafka, CDC, and data lakes. I've seen data architecture evolve from rigid, centralized warehouses to agile, distributed systems.
Today, the data mesh isn't just a buzzword. It's a strategic shift in how we think about data ownership, governance, and access.
In this guide, I want to share what I've learned from real-world implementations to help others make the leap from legacy systems to scalable, distributed data mesh platforms.
I am going to use some unconventional examples to make this read exciting, fun, and understandable. To help illustrate the evolution, I'll be using kitchen and food metaphors, concepts familiar to all of us, to walk through how data architectures have evolved over the past two decades. Let's begin!
From Michelin-Star Kitchens to Food Truck Festivals: How I See Data Architecture

1. The Traditional Data Warehouse: A Michelin-Star Kitchen
Data warehouses have existed for some time, though they required a small group of specialists to operate. They remind me of Michelin-star restaurants: tightly controlled, methodical, and consistently delivering high quality. I remember massive materialized views built on slowly changing dimensions, running on monolithic BI appliances where ETL jobs could take 20+ hours to complete.
The traditional data warehouse approach follows a linear process:
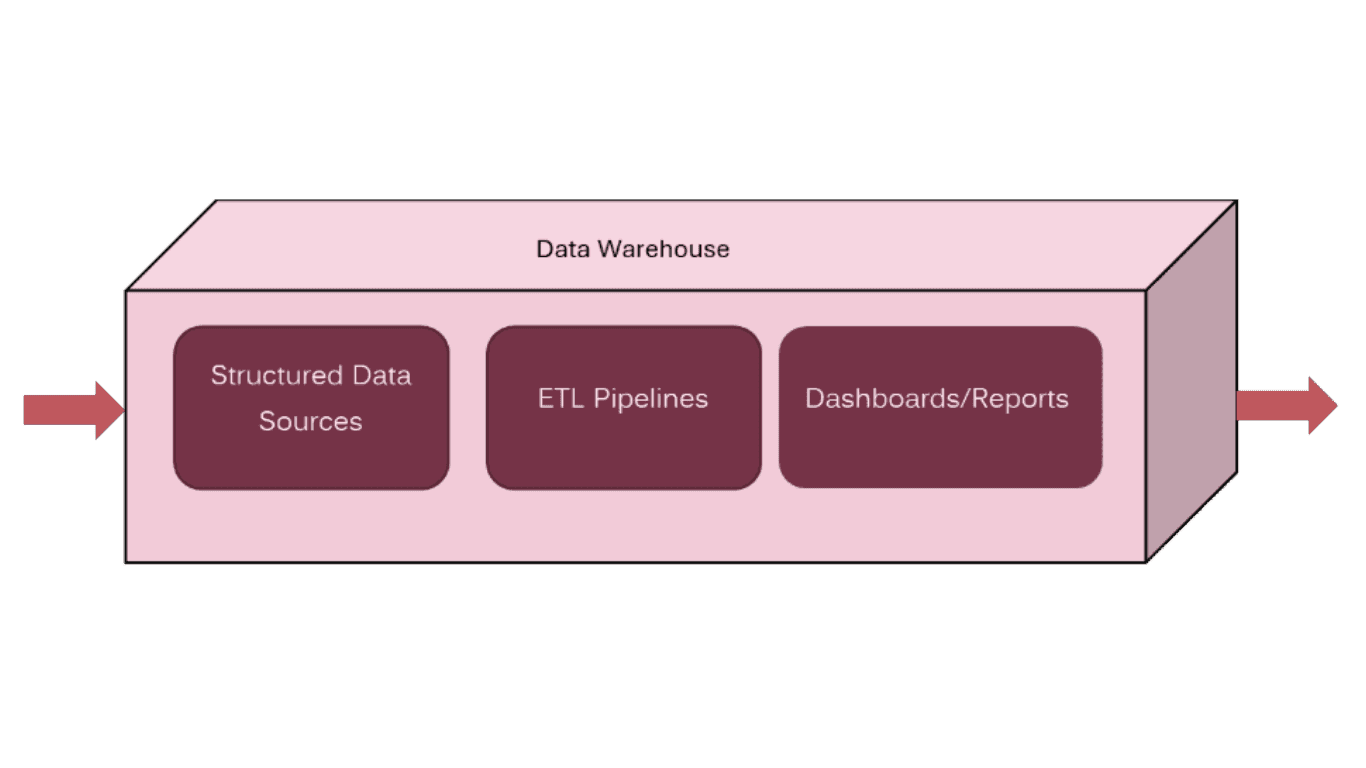
Data Sources → ETL Pipeline → Data Warehouse → Dashboards/Reports
This approach offers several benefits:
Exceptional Data Quality: Like having only the best chefs in the kitchen, data warehouses ensure no mystery or questionable data makes it to the final product
Perfect Standardization: Every output is consistently formatted and reliable
Spotless Data Cleansing: There's virtually no chance of finding corrupted or inconsistent data in your final reports
However, this approach also has significant limitations:
Slow Agility: Want something new? You'll need to fill out a request and wait for approval from BI & Analytics teams
High Latency: Your insights might arrive after you've already made the decision you needed them for
Limited Flexibility: You're restricted to what's on the predetermined menu - no custom orders or innovative approaches
2. The Data Lake: A Giant Costco Warehouse Experience
As organizations wanted more flexibility, data lakes emerged: large, inclusive environments accepting all data sources. Think of a walk-in Costco warehouse: everything’s available, but it’s easy to lose track.

The structure shifted to:
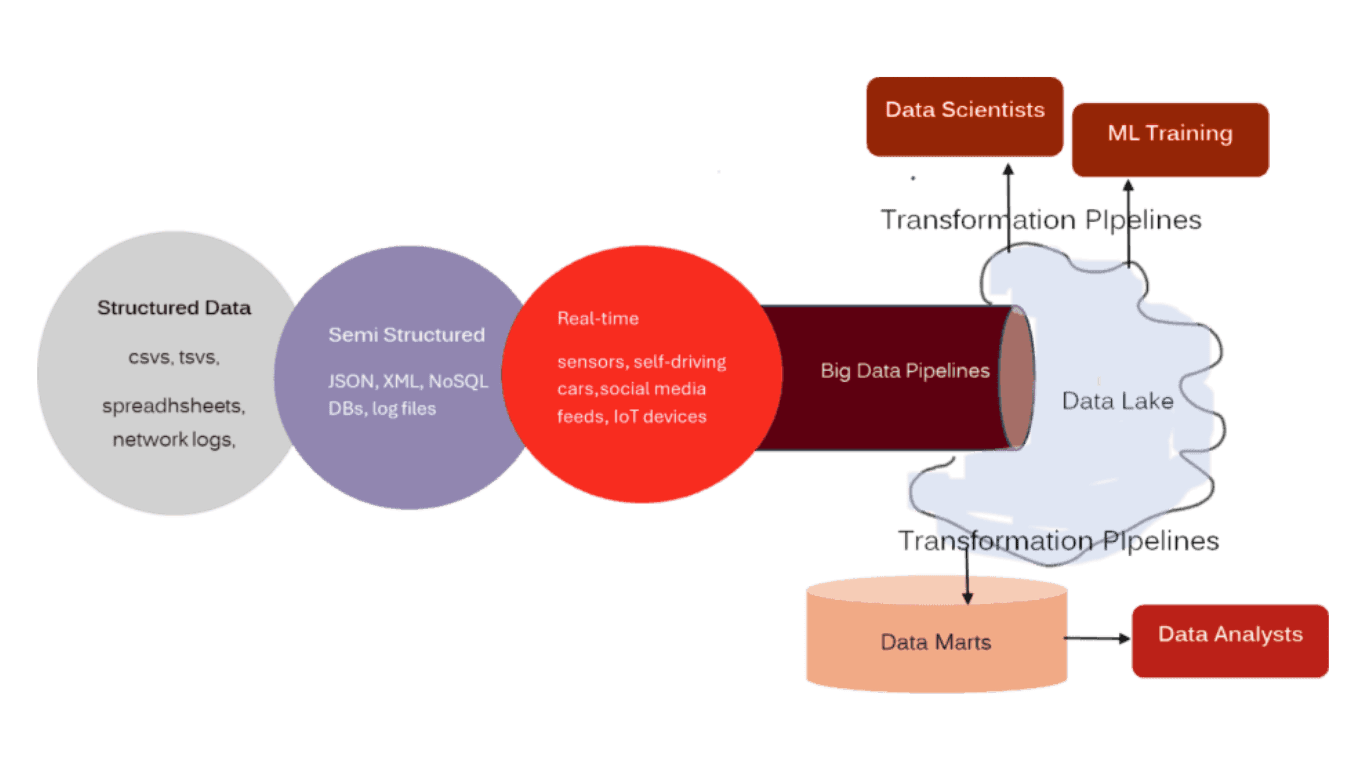
In my experience, data lakes offer remarkable advantages:
Comprehensive Data Variety: Everything's available - structured, semi-structured, and unstructured data
On-Demand Access: No waiting for data engineering teams to process your requests
Perfect for Innovation: Data scientists can experiment and explore without traditional constraints
But I've also encountered significant challenges with data lakes:
Unpredictable Data Quality: You never know what you'll get, because some data might be raw, unlabeled, or even corrupted
Expertise Required: Teams need significant technical skills to extract value from raw data
Overwhelming Complexity: Without proper governance, data lakes quickly become data swamps
3. The Data Mesh Revolution: A Food Truck Festival with Shared Infrastructure

What Makes Data Mesh Different
After working with both traditional warehouses and data lakes, I found that data mesh represents the best of both worlds. Think of it as a food truck festival with shared rules and infrastructure, but each truck (domain) operates independently while following common standards.
To understand data mesh, let’s dive deeper.
A data mesh comprises of four key components:
Domain Teams (the independent operators)
Data Products (what each domain produces)
Governance (the shared standards)
Data Consumers (who uses the data products)
The Four Pillars of Data Mesh Architecture
Successful data mesh architectures rest on four fundamental principles:
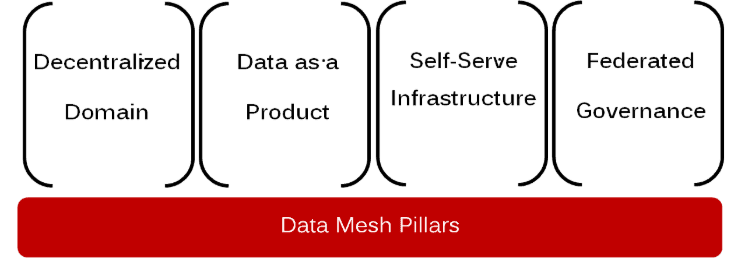
1. Domain-Oriented Ownership
Each business domain owns and manages its own data, just like each food truck manages its own kitchen and menu. In practice, this means marketing teams own customer interaction data, sales teams own transaction and pipeline data, and operations teams own logistics and supply chain data.
2. Data as a Product: The Core Data Mesh Concept
Data is delivered with quality, documentation, and clear ownership - similar to how each food truck serves specialty dishes. This includes comprehensive documentation and metadata, quality guarantees and SLA commitments, clear data contracts and APIs, plus ongoing maintenance and support.
3. Self-Serve Infrastructure
Teams use shared tools to build and manage data products independently, like food trucks sharing festival utilities. This includes common data processing platforms, shared monitoring and observability tools, standardized deployment pipelines, and unified security and access controls.
4. Federated Governance
Shared standards ensure security and compliance across all domains, similar to festival rules ensuring food safety and a great experience for everyone. This includes common data quality standards, unified security policies, standardized metadata formats, and consistent privacy and compliance controls.
What is a Data Product?
Understanding Data Products in Practice
When working with non-technical stakeholders, I explain data products like signature dishes at a restaurant. Each data product consists of several key components:
The ingredients (Data Sources)
These are the raw materials - where your data originates. These might include customer databases, transaction logs, external APIs, IoT sensor data, and third-party data feeds.
The Recipe (Configuration)
This defines how data is prepared and processed through data transformation rules, quality validation checks, processing schedules, and error handling procedures.
The Cooking Process (Processing)
The actual transformation and enrichment steps typically involve data cleansing and normalization, feature engineering, aggregation and summarization, plus real-time or batch processing capabilities.
The Plated Dish (Published Data)
The final, ready-to-use data product that consumers can access includes clean, validated datasets, APIs for real-time access, comprehensive documentation and metadata, plus usage examples and tutorials.
Quality Assurance (Monitoring)
Ensuring data remains fresh, accurate, and available is implemented through automated data quality checks, performance monitoring, alerting systems, and usage analytics.
The Menu (Reusability)
Data products can be shared and reused by many teams, similar to how popular dishes appear on multiple menus. This can be achieved via Data Contracts API
For instance, a 'Customer 360' data product might combine CRM data, web analytics, and support tickets into a single, governed view that marketing, sales, and support teams can all consume through standardized APIs.
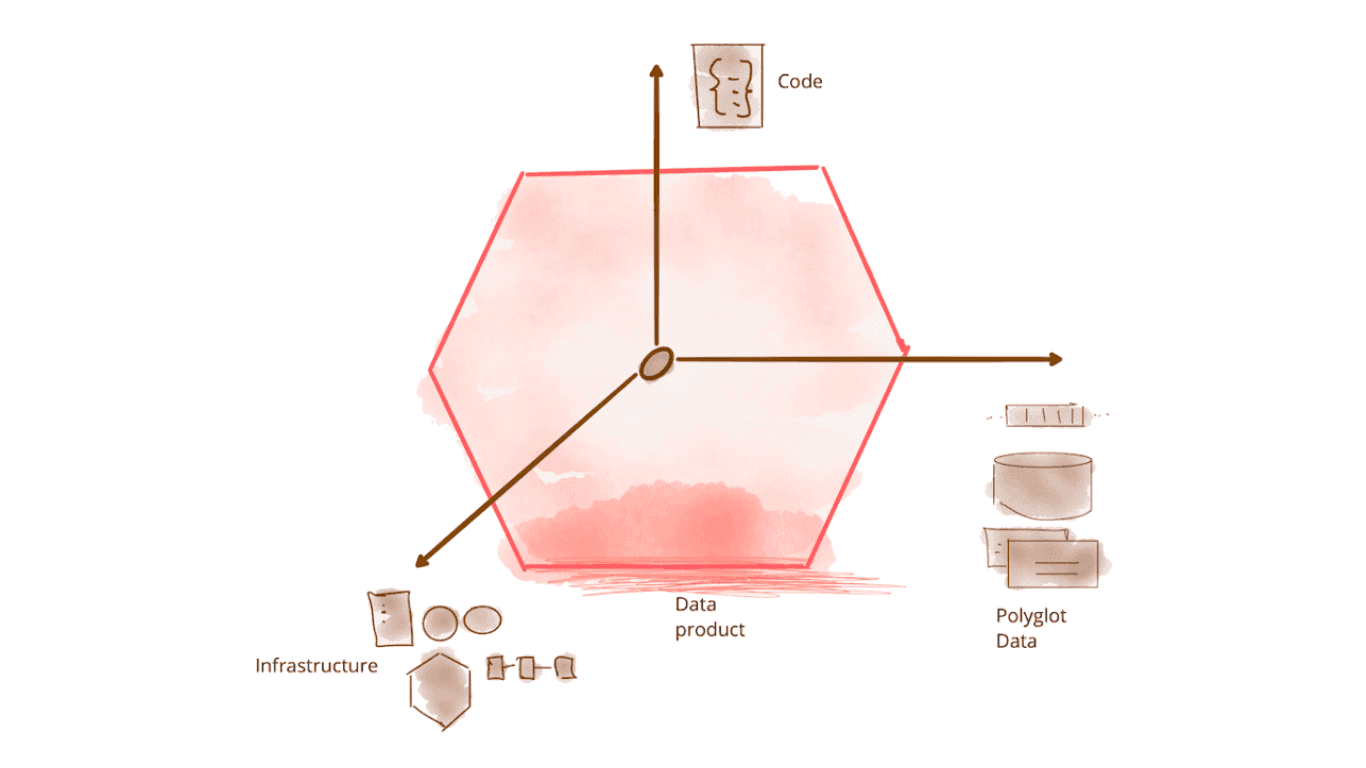
Understanding Declarative Data Products
Declarative data products represent a significant advancement in how we define and manage data pipelines. Rather than writing imperative code that describes how to process data, declarative data products specify what the end result should look like. Think of it as ordering from a menu rather than writing cooking instructions: you describe what you want, and the platform handles the execution details.
Key Components of Declarative Data Products
Effective declarative data products include:
Process Configuration
Process configuration involves establishing internal and external dependencies with clear specification of data sources and downstream consumers, defining data object definitions through structured schemas and data contracts, and implementing schedule and SLA management with automated scheduling that includes built-in SLA monitoring and alerting.
Modular Architecture
The modular architecture supports multiple data objects for complex data products with multiple output datasets, enables sub-data product grouping for logical organization of related data objects, and provides reusable components with shared processing logic and transformation functions.
Publishing and Discovery
Publishing and discovery features include automatic publishing with seamless integration with data catalogs and discovery systems, reference management that provides automatic dependency tracking and lineage management, and version control with built-in versioning and change management capabilities.
Benefits of Declarative Approach
The declarative approach offers several key advantages.
Teams experience reduced complexity by focusing on business logic rather than infrastructure concerns.
Improves maintainability: Changes to requirements become easier to implement and test.
Better governance ensures automatic compliance with organizational standards and policies.
Enhanced collaboration provides clear, readable specifications that non-technical stakeholders can understand.
The Future of Data Mesh
Emerging Trends I'm Observing
As I continue working with data mesh architectures, I'm seeing several important trends:
1. Increased Automation
Intelligent Data Discovery: AI-powered tools that automatically identify and classify data assets
Automated Quality Monitoring: Machine learning systems that detect and prevent data quality issues
Self-Healing Pipelines: Systems that automatically recover from common failures
2. Enhanced Governance
Policy as Code: Governance rules implemented as executable code
Dynamic Compliance: Real-time compliance monitoring and enforcement
Privacy by Design: Built-in privacy controls and data protection mechanisms
Low-Code/No-Code Platforms: Visual tools that enable business users to create data products
Integrated Development Environments: Comprehensive platforms that streamline the entire data product lifecycle
Advanced Testing Frameworks: Sophisticated tools for testing data products in production-like environments
3. Agentic Data Mesh
Agentic data mesh represents the convergence of AI agents with distributed data architecture. In this emerging paradigm, autonomous agents can discover, access, and orchestrate data products across domains to fulfill complex analytical requests. Rather than humans manually stitching together data from multiple domains, AI agents navigate the mesh, understand data contracts, and compose multi-domain insights automatically.
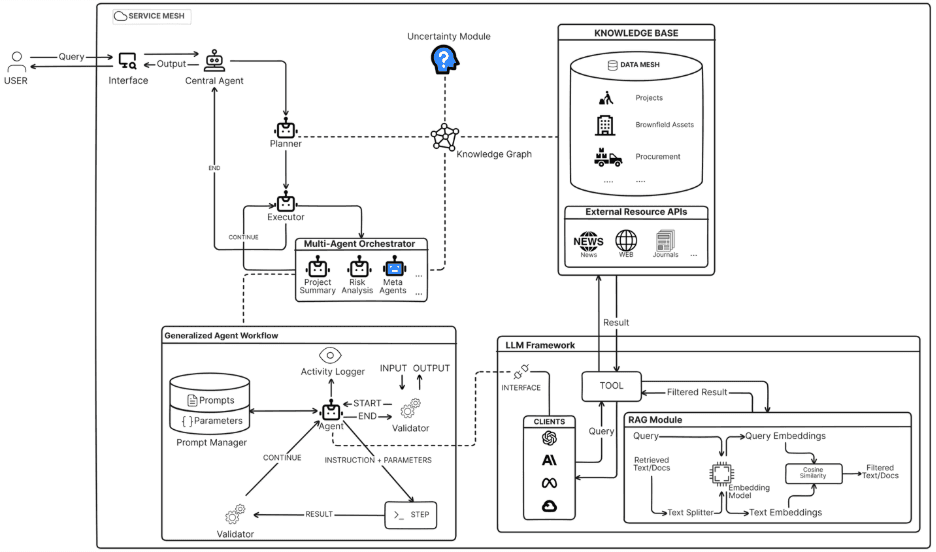
Multi Agent Generalized Workflow
Image credit: https://arxiv.org/html/2412.00224v1
This approach enables:
Natural language queries that span multiple business domains
Automated data product composition based on user intent
Intelligent caching and optimization of cross-domain queries
Self-service analytics without requiring deep technical knowledge
Data Mesh Best Practices
Organizations considering data mesh adoption should:
Start Small: Begin with a pilot project in a single domain
Build Robust Services: Bettle test your platform services with stable releases, unit tests, code coverage, and CI/CD processes.
Test, Test and Test: Build, deploy, and test all platform features on a test data mesh node for DEV/UAT/PROD before rolling out features on consumer data mesh nodes.
Invest in Training: Ensure teams understand data mesh principles before implementation.
Focus on Governance: Establish clear standards and policies from the beginning.
Choose the Right Technology Stack: Select tools that support distributed architectures.
Plan for Cultural Change: Address organizational resistance to distributed data ownership.
Summary: Data Mesh and Beyond
The transition from traditional data warehouses to data mesh isn't always easy, but the benefits are substantial.
Organizations that successfully implement data mesh architectures see improved data quality, faster time-to-insight, better cross-team collaboration, and increased innovation capabilities.
For me, data mesh isn’t just a new architecture. It’s a philosophy. It brings data closer to those who need it, when they need it, and in the form they can use.
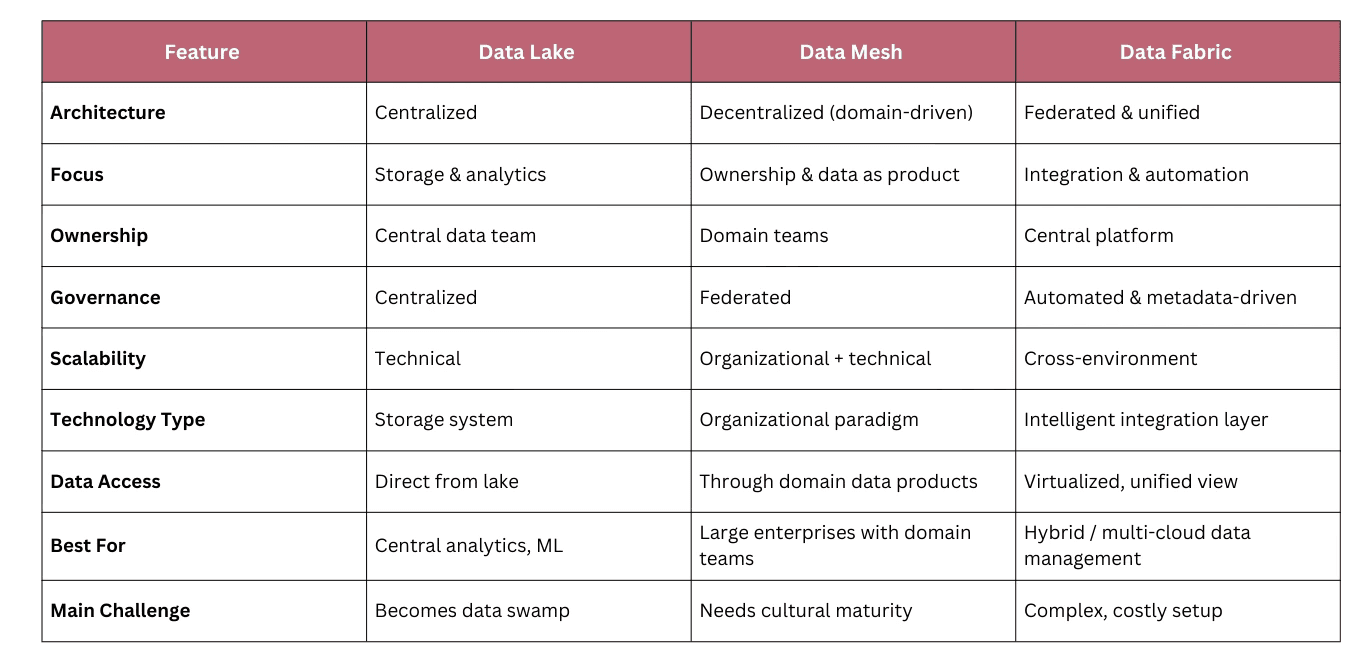
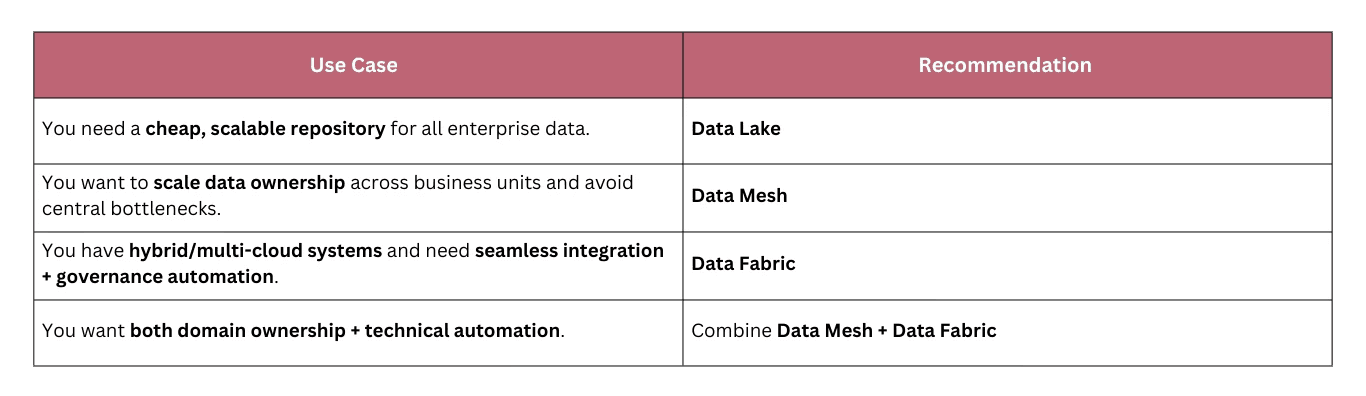
We will save a deep dive into Data Fabric for another time, but I want to ensure you get immediate value from this guide. Below is a comparison of key data architectures to help you determine when each approach is most effective.
When to Use What
One could argue we're not just leaving behind centralized control. We're gaining autonomy, agility, and innovation. The food truck festival is open, and every domain has a chance to cook up something great.
The future of data is distributed and autonomous. Data mesh is how we get there.
In our next article, we'll dive deep into the practical implementation of data mesh platforms, exploring real-world architecture, tooling decisions, and platform enablement strategies that make data mesh successful in production environments.
Until next time, keep building better data systems 😊





